


Quality Estimation Tools on the Market in 2024
A brief investigation into machine translation quality estimation and tools available to localization teams.

What is machine-translation quality estimation?
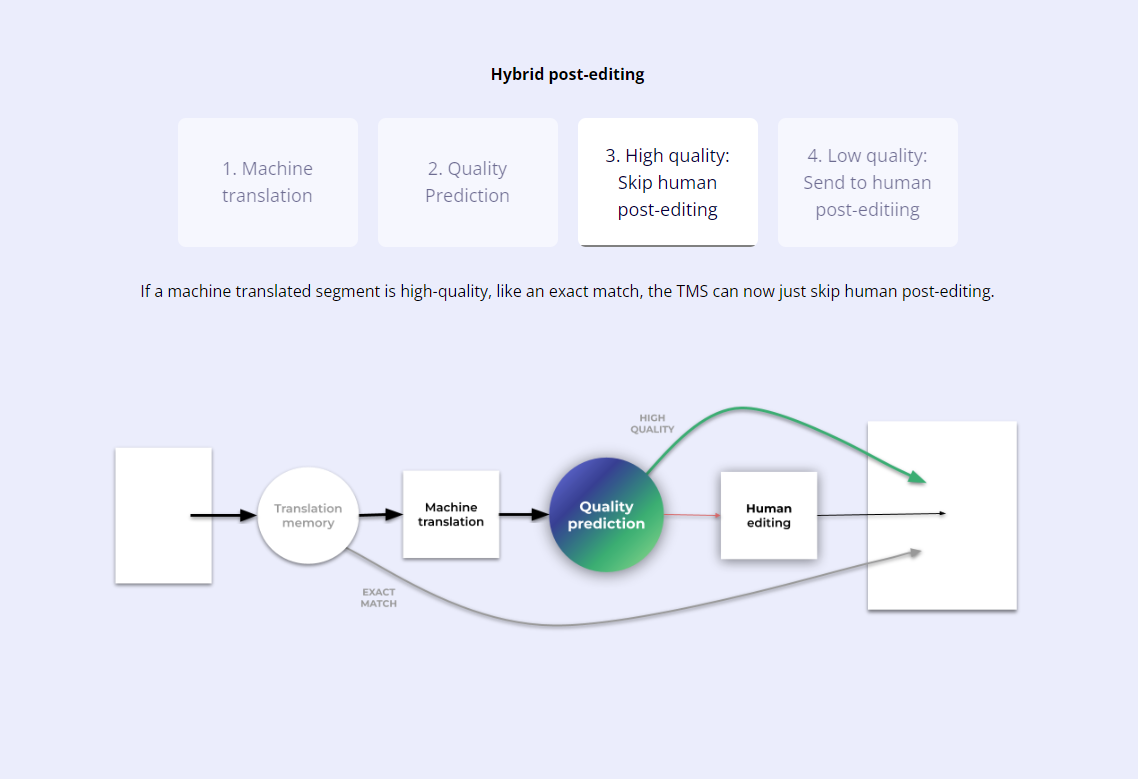
Quality estimation is the prediction of translation quality by a machine without any reference translations. A common use case for quality estimation in localization is the quality scoring of machine-translated output to flag segments that are likely to require human editing, a workflow sometimes called hybrid post editing. Proponents of quality estimation claim that it enables teams to maximize their resources by focusing on the problematic segments and reducing resources used on the least likely problematic segments.
Applications of quality-estimation
Enhanced MTPE workflows with quality-score categorizations for linguistic triage
Automated approval of segments with high confidence of quality scores
Estimating post-editing effort
Dynamic MT engine selection
Quality estimation of translation memory outputs
Quality estimation of translation memory entries for translation memory cleaning
Quality estimation tools available as of February, 2024
The second half of my investigation is to understand the quality evaluation options available to localization teams right now with a focus on:
TMS tools with native capabilities
API-connectable models
Translation Management Systems with native quality estimation capabilities
Phrase Strings and Phrase TMS
Phrase’s quality evaluation technology is marketed as Phrase Quality Performance Score (QPS) and it is available in Phrase TMS and Phrase Strings. Phrase QPS can be applied to human translations and machine translations for estimating quality at the segment level and for entire documents.
Phrase’s QPS scoring-metric structure relies on the Multidimensional Quality Metrics framework for the evaluation of translation quality. In Phrase’s own words, Phrase QPS scores… “(reflect) what it believes the translation would score were it reviewed by a human using the MWM evaluation framework.” See more here: link . In Phrase Strings, quality scores between 0 and 100 are generated for each string in real-time. In Phrase TMS, the QPS can be implemented on machine translation post editing workflows, and automatic segment confirmation can be applied to customized QPS thresholds to eliminate unnecessary MTPE review.
Unbabel
Unbable offers quality estimation, but their documentation and blog posts don’t reveal too much about how they implement MTQE in their platform and services. However, Unbabel seems to be a leader amongst the other language technology companies in AI and NLP development.
It was Unbabel who developed the COMET scoring method and Unbabel is also behind the open-source QE model OpenKiwi.
Quality Estimation engines with API connectivity
TAUS DeMT Estimate API
TAUS offers an API connectable, proprietary generic QE model and proprietary custom QE model that users can integrate into their TMS and CAT tools. However, there are out-of-the-box integrations with Memoq and blackbird.io.
An interesting capability of the deMT Estimate API is the ability to customize and choose a scoring framework. The TAUS QE Score is an AI system that evaluates the semantic similarity between source and target text and can return a score between 0 and 1.
Another option is the COMET score, more commonly used for comparing MT model performance because of its reliance on reference translations. COMET scoring was developed by Unbabel and there is even a “ready to use” model available as open-source. The third option offered is a custom scoring model.
ModernMT
Translated’s ModernMT’s MT Quality Estimator (T-QE) provides quality scores at the segment level and has out-of-the-box connectors with Memoq, MateCat and RWS Trados Studio, but can be integrated into any software using their API.
ModernMT cliams that their model was trained on over 5 billion sentences from corpora that were translated with MT and then corrected by linguists. Then, the AI model learned from the error correction patterns to predict which segments are likely to require correction.
ModelFront
Not unlike the two providers above, ModelFront offers an API service for quality estimation. One difference I noted between ModelFront and the preceding providers is that ModelFront advocates for a a hybird post-editing process. The hybrid process they advocate for is to skip post editing of segments with a high-quality estimate score, essentially treating them like exact translation memory matches, and then to post-edit only the low quality-estimated segments.
ModelFront claims that their hybrid post-editing process yields 5X faster turnaround times, 5X translation volume on the same budget, and human quality translations. ModelFront claims to integrate with Memoq, Crowdin, Trados, XTM and others.
En fin
There are TMSs with native quality estimation capabilities and third-party engines that can plug into a TMS. So what is the difference and why choose one over the other?
IMO, native quality-estimation capabilities are convenient but will lack customization. A low-maturity localization team may use them effectively out of the box and until they outgrow the native capabilities of their TMS. What ModernMT, ModelFront, and TAUS deMT API are providing is more customizability for enterprise use cases.